

9月8日,中国科学院自动化研究所宣布联合沐曦MetaX,推出全球首款类脑脉冲大模型“瞬悉1.0”(SpikingBrain-1.0),首次在国产千卡GPU平台上完成全流程训练与推理,突破Transformer架构依赖,实现超长序列推理效率数量级提升。
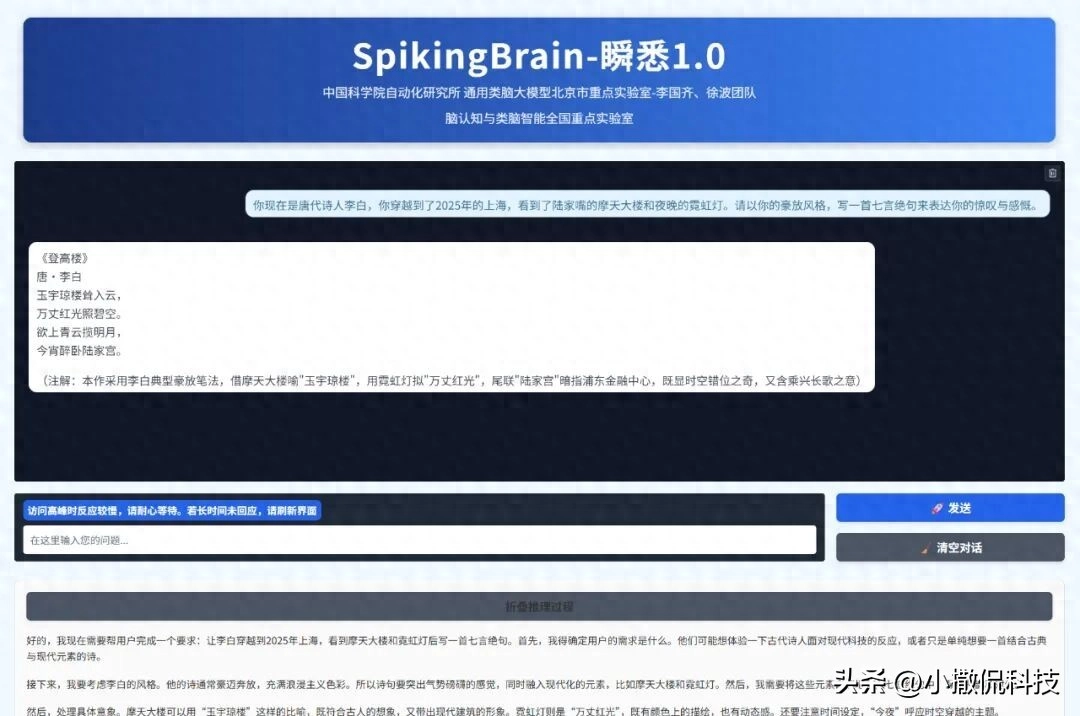
这一突破直指Transformer架构的核心痛点:其训练开销随序列长度呈平方级增长,推理显存占用线性增加,导致长文本处理成本极高。而“瞬悉1.0”借鉴大脑神经元工作机制,提出“内生复杂性”理论,通过脉冲神经元动态计算,将训练复杂度降至线性水平。其最惊人表现是数据效率——仅需主流模型2%的预训练数据,即在多任务语言理解(MMLU、CMMLU)和常识推理(ARC、HS)任务上媲美开源Transformer模型性能。
推理效率提升更为颠覆:在100万Token长度下,生成第一个Token的时间比Transformer加速26.5倍,400万Token下超100倍;甚至在手机CPU端,64k-256k序列解码速度较Llama3.2提升4-15倍。这意味着未来手机可直接本地处理百万字文档或小时级视频分析,无需依赖云端算力。
技术背后是国产生态的全面突围。
模型适配沐曦国产GPU曦云C550集群,自研Triton算子库与通信原语,首次实现从架构设计到硬件落地的全链路自主可控。其超长序列能力在医学文档、DNA分析、物理模拟等领域具显著优势,或重塑科研与工业场景的AI应用范式。
然而挑战犹存:脉冲模型的动态稀疏特性虽带来能效优势(7B模型稀疏度69.15%),但算法稳定性与生态适配仍需验证;且开源社区能否快速接纳非Transformer架构,亦决定其技术影响力边界。
类脑模型突破是否意味着AI将告别“暴力计算”时代?人类能否真正模拟大脑智慧?欢迎分享你的观点!
本文内容来源:中国科学院自动化研究所公告、SpikingBrain技术报告、沐曦MetaX合作声明
文是楼上发的,图是楼上帖的,寻仇请认准对象。
有些是原创,有些图文皆转载,如有侵权,请联系告知,必删。
如果不爽,请怼作者,吐槽君和你们是一伙的!请勿伤及无辜...
本站所有原创帖均可复制、搬运,开网站就是为了大家一起乐乐,不在乎版权。
对了,本站小水管,垃圾服务器,请不要采集,吐槽君纯属用爱发电,经不起折腾。

















暂无评论内容