

DeepSeek-R2 姗姗来迟,业内人士似乎等不及了?这不,德国 TNG Technology Consulting GmbH 公司(下称 TNG)基于 DeepSeek R1-0528 新版本,推出了一款速度提升 200% 的 DeepSeek-TNG R1T2 Chimera 模型(下称 R1T2)。R1T2 是一款拥有 6710 亿参数的开源混合模型,也是 TNG 团队 Chimera 大模型系列中的最新型号。DeepSeek-R1-0528 因其扩展的思维链推理而倾向于给出长篇大论的详细回答,而本次 R1T2 的设计更加简洁,它在使用明显更少的词汇的同时,也能给出同样智能的回答。另外,R1T2 再次使用了由 TNG 团队提出的集合专家(AoE,Assembly-of-Experts)方法。
(来源:arXiv)
值得注意的是,TNG 的联合创始人亨利克·克莱格斯(Henrik Klagges)是相关论文的第一作者,领英页面显示他联合创办 TNG 已有 24 年之久。

图 | 相关论文(来源:arXiv)
1994 年,克莱格斯从英国牛津大学毕业后,于 2001 年创办了 TNG。目前,该公司拥有 917 名员工,99.9% 的员工为学术人员,并且超过 50% 的员工拥有数学、物理和计算机科学的博士学位。也就是说,作为一个基于 DeepSeek 做变体模型的团队,TNG 并不是一个无名小卒。
图 | TNG 联合创始人亨利克·克莱格斯(Henrik Klagges)的领英界面(来源:领英)
此前,在相关实验结果以及混合专家(MoE,Mixture of Experts)模块化结构的启发之下,TNG 团队将 DeepSeek-V3-0324 和 DeepSeek-R1 的路由专家张量进行合并,由此打造了 DeepSeek-R1T-Chimera 模型(下称 R1T)。而本次推出的 R1T2 在保留 DeepSeek-R1 推理性能的同时,在效率和速度方面实现了显著提升。在不损失或几乎不损失智能的情况下显著降低了冗余度,这意味着它能产生更短的响应,从而能够直接转化为更快的推理速度和更低的计算成本。
作为 R1T 的后续版本,R1T2 还引入了一种新的“Tri-Mind”配置,该配置集成了三个父模型:DeepSeek-R1-0528、DeepSeek-R1 和 DeepSeek-V3-0324。
据介绍,R1T2 是在没有进一步微调或重新训练的情况下构建的,它继承了 DeepSeek-R1-0528 的推理能力、DeepSeek-R1 的结构化思维模式以及 DeepSeek-V3-0324 的简洁指令导向的行为特性,因此是一个更高效、更强大的模型。
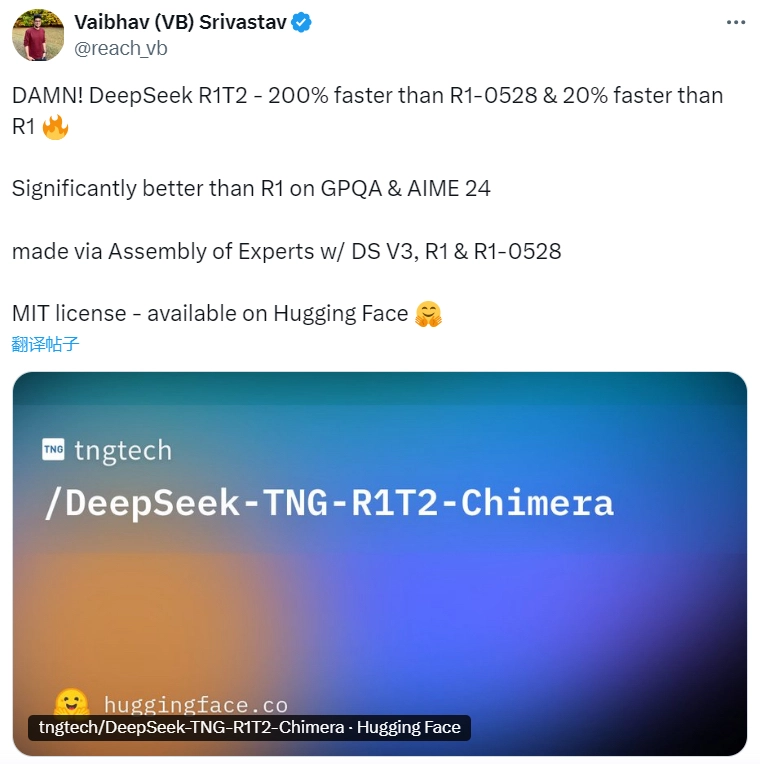
AI 开发者社区对此反应也比较积极,Hugging Face 的高级领导 Vaibhav(VB)Srivastav 在 X 上写道:“太棒了!DeepSeek R1T2——比 R1-0528 快 200%,比 R1 快 20%。在 GPQA 和 AIME 24 数据集上的表现明显优于 R1,并采用 DS V3、R1 和 R1-0528 组合打造了集合专家架构,而且它使用 MIT 许可协议,目前已在 Hugging Face 上开放。”
(来源:X)
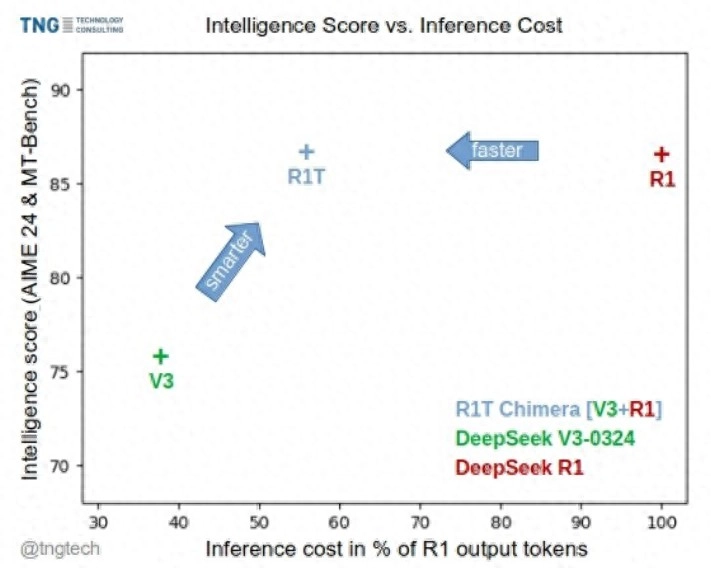
TNG 团队提供的基准比较结果显示,在 AIME-24、AIME-25 和 GPQA-Diamond 测试集的评估下,R1T2 的推理性能达到了其最智能父模型 DeepSeek-R1-0528 的 90% 至 92%。
与此同时,TNG 团队并不侧重于原始处理时间或每秒处理的 token 数量,而是以每个答案的输出 token 数量来衡量“速度”,他们将这视为一种能够同时反映成本和延迟的实用指标。R1T2 生成响应所需的 token 量大约为 DeepSeek-R1-0528 的 40%,这意味着输出长度减少了 60%,从而能够直接减少推理时间和计算负载,进而能使响应速度提高 200%。与原始的 DeepSeek-R1 相比,R1T2 的平均简洁度也提高了约 20%,这为高通量或成本敏感的部署带来了显著的效率提升。并且,这种高效性并未以牺牲智能为代价。正如 TNG 团队的基准图表所展示的,R1T2 在“智能 vs. 输出成本”曲线上处于一个理想区域。它在保持推理质量的同时能够大幅减少冗余输出,这一特性对于那些对推理速度、吞吐率和成本都有严格要求的企业级应用至关重要。
(来源:arXiv)

集合专家与混合专家有何不同?
如前所述,TNG 团队曾提出了集合专家(AoE,Assembly-of-Experts)方法,这是一种通过有选择地合并多个预训练模型的权重张量(内部参数)来构建大模型的技术。
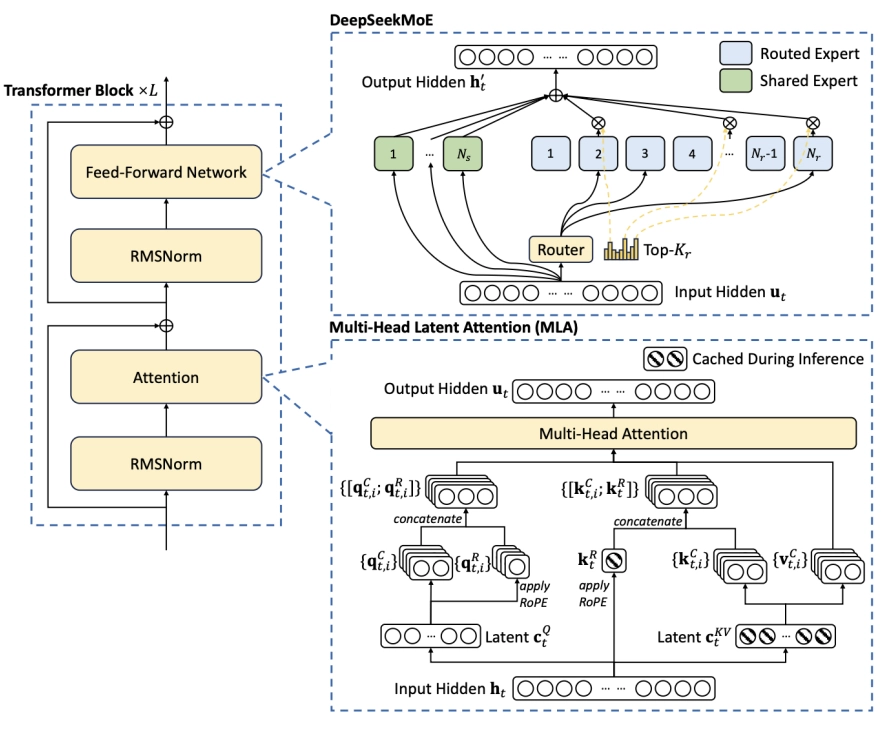
很多人对于混合专家(MoE,Mixture-of-Experts)并不陌生,MoE 是一种架构设计,其中不同的组件或“专家”会根据输入有条件地被激活。对于典型的 MoE 大模型比如 DeepSeek-V3 和 Mixtral来说,在任何给定 token 的前向传递过程中,只有模型专家层的一个子集处于活动状态(例如,256 个中的 8 个)。这使得超大规模模型在实现更高参数量和更强专业化的同时,仍能保持可控的推理成本,因为每个 token 只需激活网络中的一小部分子模块。
在预训练期间,大模型计算一个 8 位权重需要 10^13 至 10^15 次浮点运算(FLOPs,Floating-Point Operations),不仅成本极高而且效率低下。正是为了更好地利用对预训练模型的大量投资,TNG 团队开发了 AoE。AoE 是一种模型融合技术,而非一种架构。它通过有选择地插值多个预训练的 MoE 模型的权重张量,以用于从这些模型中创建一个新模型。
该方法能够在线性时间内创建现有 MoE 父模型的高效子模型变体。模型权重张量会被单独进行插值处理,从而能够增强或抑制父模型的语义特征。通过改变从父模型中提取的权重比例,TNG 团队观察到 AoE 子模型的一些特性会逐渐变化,而其他行为特征则会发生急剧转变。
另据悉,AoE 中的“专家”指的是正在合并的模型组件,通常是 MoE 层中路由的专家张量,而非在运行时动态激活的专家。TNG 团队对于 AoE 的实现主要侧重于合并路由专家张量,这是模型中负责专门推理的部分,同时通常会保留来自 DeepSeek-V3-0324 等更快模型中更高效的共享层和注意力层。这种方法使得 TNG 团队生成的 R1T 和 R1T2 这一系列 Chimera 模型能够继承推理能力,同时避免了最强父模型的冗长性或延迟问题。
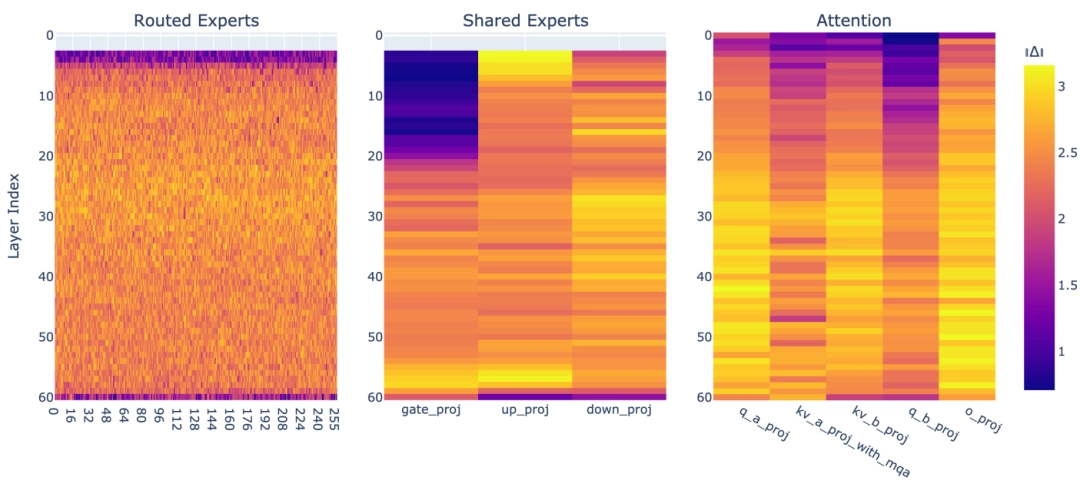
(来源:arXiv)

欧洲企业或面临使用受限
对于 CTO、AI 平台所有者、工程主管和 IT 采购团队而言,R1T2 带来了切实的益处和战略选择:
其一,推理成本更低:由于每项任务的输出 token 更少,R1T2 减少了 GPU 时间和能耗,直接节省了基础设施成本,这在高吞吐量或实时环境中尤为重要。
其二,高推理质量无冗余:R1T2 保留了 DeepSeek-R1-0528 等顶级模型的大部分推理能力,但没有它们冗长的缺点。这非常适合数学、编程、逻辑等结构化任务,在这些任务中,简洁的答案更受欢迎。
其三,开源且可修改:MIT 许可证允许完全的部署控制和定制,支持在受监管环境或隔离环境中进行私有托管、模型对齐或进一步训练。
其四,新兴的模块化:AoE 方法预示着一个模型将以模块化方式构建的未来。在这种未来场景中,企业无需从头开始重新训练,而是可以通过重组现有模型的优势来组装出专门的变体。
需要注意的是,R1T2 依赖函数调用、工具使用或高级代理编排的企业应注意当前的局限性,尽管未来的 Chimera 更新可能会弥补这些不足。
目前,TNG 团队已通过 OpenRouter 和 Chutes 等平台提供了早期的 Chimera 变体,这些平台每天处理数十亿个 token。而 R1T2 的发布标志着这一公开可用性工作的进一步发展。
TNG 团队指出,尽管该模型非常适合通用推理任务,但由于继承自 DeepSeek-R1 系列的限制,目前不建议将其用于需要函数调用或工具使用的场景。
作为一家欧洲公司,TNG 团队还建议欧洲用户评估其是否符合将于 2025 年 8 月 2 日生效的《欧盟 AI 法案》的规定。在欧盟运营的企业应审查相关规定,若无法满足要求,则应考虑在该日期后停止使用该模型。
然而,在美国国内运营并为美国用户或其他国家用户提供服务的美国公司,不受《欧盟 AI 法案》条款的约束,这将使其在使用和部署这一免费、快速的开源推理模型时拥有相当大的灵活性。但是,如果他们为欧盟用户提供服务,则《欧盟 AI 法案》中的一些条款仍然适用。
总的来说,之前是国内开发者基于国外模型做变体研究,现在逐渐开始反过来,这也映照了中国科技从跟跑到并肩跑,再到逐渐能起到一定引领作用的大趋势。
参考资料:
相关论文:
https://arxiv.org/pdf/2506.14794
Hugging Face:https://huggingface.co/tngtech/DeepSeek-TNG-R1T2-Chimera
https://x.com/reach_vb/status/1940536684061643239
https://www.linkedin.com/in/vaibhavs10/
本文转自头条号DeepTech深科技
文是楼上发的,图是楼上帖的,寻仇请认准对象。
有些是原创,有些图文皆转载,如有侵权,请联系告知,必删。
如果不爽,请怼作者,吐槽君和你们是一伙的!请勿伤及无辜...
本站所有原创帖均可复制、搬运,开网站就是为了大家一起乐乐,不在乎版权。
对了,本站小水管,垃圾服务器,请不要采集,吐槽君纯属用爱发电,经不起折腾。
















暂无评论内容