

微软发布了新一代人工智能芯片 Maia 200,这款芯片有望成为英伟达领先处理器以及亚马逊和谷歌等云服务竞争对手产品的潜在替代品。
Maia 200 的发布距离微软宣布开发首款人工智能芯片 Maia 100 已过去两年,但 Maia 100 从未向云客户开放租赁。微软云和人工智能执行副总裁 Scott Guthrie 周一在一篇博客文章中表示,这款新芯片“未来将面向更广泛的客户群体”。
Guthrie 称 Maia 200 是“微软迄今为止部署的最高效的推理系统”。开发者、学者、人工智能实验室以及开源人工智能模型贡献者均可申请软件开发工具包的预览版。
微软表示,由 Mustafa Suleyman 领导的超级智能团队将使用这款新芯片。此外,面向商业生产力软件套装的 Microsoft 365 Copilot 插件以及用于构建人工智能模型的 Microsoft Foundry 服务也将使用该芯片。
云服务提供商面临着来自 Anthropic 和 OpenAI 等生成式人工智能模型开发商以及基于这些热门模型构建人工智能代理和其他产品的公司的激增需求。数据中心运营商和基础设施提供商正努力提升计算能力,同时控制能耗。
微软正在为其美国中部数据中心配备 Maia 200 芯片,之后将在美国西部 3 区部署,并陆续扩展到其他地区。
这些芯片采用台积电 (TSMC) 的 3 纳米工艺制造。每台服务器内部连接四个这样的芯片。它们使用以太网线连接,而非 InfiniBand 标准。英伟达在 2020 年收购 Mellanox 后开始销售 InfiniBand 交换机。
Guthrie 写道,该芯片的性能比同等价位的同类产品高出 30%。微软表示,每个 Maia 200 芯片都比亚马逊网络服务 (AWS) 的第三代 Trainium 人工智能芯片或谷歌的第七代张量处理单元 (GPU) 拥有更大的高带宽内存。格思里写道,微软可以通过将多达 6,144 个 Maia 200 芯片连接在一起,实现高性能,同时降低能耗和总体拥有成本。
2023 年,微软展示了其 GitHub Copilot 代码助手可以在 Maia 100 处理器上运行。
专为推理而打造的 AI 加速器
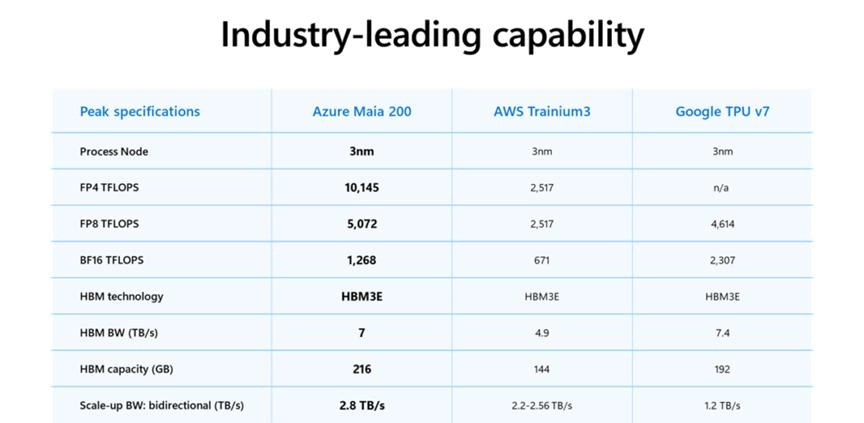
今天,我们(指代微软,下同)荣幸地推出 Maia 200,这是一款突破性的推理加速器,旨在显著提升 AI 代币生成的经济效益。Maia 200 是一款强大的 AI 推理加速器:它采用台积电 3nm 工艺制造,配备原生 FP8/FP4 张量核心,重新设计的内存系统包含 216GB HBM3e(读写速度高达 7TB/s)和 272MB 片上 SRAM,以及能够确保海量模型快速高效运行的数据传输引擎。这使得 Maia 200 成为目前所有超大规模数据中心中性能最高的自研芯片,其 FP4 性能是第三代 Amazon Trainium 的三倍,FP8 性能更是超越 Google 第七代 TPU。Maia 200 也是微软迄今为止部署的最高效推理系统,其每美元的性能比我们目前部署的最新一代硬件提升了 30%。
Maia 200 是我们异构 AI 基础设施的一部分,它将支持多种模型,包括来自 OpenAI 的最新 GPT-5.2 模型,从而为 Microsoft Foundry 和 Microsoft 365 Copilot 带来更高的性价比。微软超级智能团队将利用 Maia 200 进行合成数据生成和强化学习,以改进下一代内部模型。对于合成数据管道用例,Maia 200 的独特设计有助于加快高质量、特定领域数据的生成和筛选速度,从而为下游训练提供更新鲜、更具针对性的信号。
Maia 200 已部署在我们位于爱荷华州得梅因附近的美国中部数据中心区域,接下来将部署位于亚利桑那州凤凰城附近的美国西部 3 数据中心区域,未来还将部署更多区域。Maia 200 与 Azure 无缝集成,我们正在预览 Maia SDK,其中包含一套完整的工具,用于构建和优化 Maia 200 模型。它包含全套功能,包括 PyTorch 集成、Triton 编译器和优化的内核库,以及对 Maia 底层编程语言的访问。这使开发人员能够在需要时进行细粒度控制,同时实现跨异构硬件加速器的轻松模型移植。
Maia 200 采用台积电先进的 3 纳米工艺制造,每颗芯片包含超过 1400 亿个晶体管,专为大规模 AI 工作负载量身打造,同时兼顾高性价比。Maia 200 在这两方面都力求卓越。它专为使用低精度计算的最新模型而设计,每颗 Maia 200 芯片在 4 位精度 (FP4) 下可提供超过 10 petaFLOPS 的性能,在 8 位精度 (FP8) 下可提供超过 5 petaFLOPS 的性能,所有这些都控制在 750W 的 SoC TDP 范围内。实际上,Maia 200 可以轻松运行当今最大的模型,并且为未来更大的模型预留了充足的性能空间。

至关重要的是,FLOPS(浮点运算次数)并非提升人工智能速度的唯一要素。数据输入同样重要。Maia 200 通过重新设计的内存子系统解决了这一瓶颈问题。Maia 200 的内存子系统以窄精度数据类型、专用 DMA 引擎、片上 SRAM 和用于高带宽数据传输的专用片上网络 (NoC) 架构为核心,从而提高了令牌吞吐量。
在系统层面,Maia 200 引入了一种基于标准以太网的新型双层可扩展网络设计。定制的传输层和紧密集成的网卡无需依赖专有架构,即可实现卓越的性能、强大的可靠性和显著的成本优势。
每个加速器都会暴露:
- 2.8 TB/s 双向专用扩展带宽
- 可预测的、高性能的跨集群集体操作,最多可达 6,144 个加速器
- 该架构可为密集推理集群提供可扩展的性能,同时降低 Azure 全球集群的功耗和总体拥有成本。
每个托架内,四个 Maia 加速器通过直接的非交换链路完全连接,从而实现高带宽的本地通信,以获得最佳推理效率。机架内和机架间联网均采用相同的通信协议,即 Maia AI 传输协议,从而能够以最小的网络跳数实现跨节点、机架和加速器集群的无缝扩展。这种统一的架构简化了编程,提高了工作负载的灵活性,并减少了闲置容量,同时在云规模下保持了一致的性能和成本效益。

微软芯片开发计划的核心原则是在最终芯片上市之前,尽可能多地验证端到端系统。
从架构的早期阶段开始,一套精密的芯片前开发环境就指导着Maia 200的开发,它能够高保真地模拟LLM的计算和通信模式。这种早期协同开发环境使我们能够在首块芯片问世之前,将芯片、网络和系统软件作为一个整体进行优化。
我们从设计之初就将 Maia 200 定位为数据中心内快速、无缝的可用性解决方案,并对包括后端网络和第二代闭环液冷热交换器单元在内的一些最复杂的系统组件进行了早期验证。与 Azure 控制平面的原生集成,可在芯片和机架级别提供安全、遥测、诊断和管理功能,从而最大限度地提高生产关键型 AI 工作负载的可靠性和正常运行时间。
得益于这些投资,Maia 200 芯片首批封装件到货后数日内,人工智能模型便已在其上运行。从首批芯片到首个数据中心机架部署的时间缩短至同类人工智能基础设施项目的一半以上。这种从芯片到软件再到数据中心的端到端解决方案,直接转化为更高的资源利用率、更快的生产交付速度,以及在云规模下持续提升的每美元和每瓦性能。

Maia 200的更多细节
微软表示,Maia 200 是其首款专为应对人工智能性能挑战而设计的芯片。除了强大的运算能力外,人工智能推理还需要大量的高速内存,以及内存与处理器之间的高速连接。Maia 200 在这两方面都表现出色。
Maia 200 采用台积电 3 纳米工艺制造,热设计功耗 (TDP) 为 750 瓦。Maia 200 的核心是两个执行引擎:一个用于高吞吐量矩阵乘法和卷积的 Tile 张量单元 (TTU),支持 FP8、FP6 和 FP4 分辨率;另一个用于 SIMD(单指令多数据)指令的 Tile 向量处理器 (TVP),支持 FP8、BF16 和 FP32 处理。
TTU 和 TVP 执行引擎连接到 216GB 高带宽内存 (HBM3) 以及 272MB 片上 TSRAM(块静态随机存取存储器)。Maia 200 具有直接内存访问 (DMA) 子系统,用于保持 TSRAM 和 TTU 之间的数据流,以及一个小型块控制处理器 (TCP),用于协调 TTU 和 DMA 之间的工作。
根据Azure 工程博客上由系统与架构副总裁 Saurabh Dighe 和 AI 芯片工程副总裁 Artour Levin 撰写的关于全新 Maia 200 的深度解析文章,Maia200 架构的一个显著特征是其丰富的内存和内存层次结构。他们写道:“这种强大的片上内存资源支持各种低延迟、高带宽的数据管理策略。CSRAM 和 TSRAM 均由软件完全管理,使开发人员或编译器/运行时能够确定性地放置和固定数据,从而精确控制数据的局部性和移动性。”
Maia 200 芯片集成了片上以太网网络接口卡 (NIC),可与相邻芯片实现每秒 2.8 TB 的双向带宽。据 Dighe 和 Levin 介绍,Maia 200 采用“双层纵向扩展”拓扑结构,结合了基于以太网的纵向扩展互连,可在包含多达 6,144 个加速器的集群中实现高带宽、低延迟的通信。
Dighe 和 Levin 表示,Maia 200 的图块级处理能力,结合 DMA 和片上网络 (NoC) 功能,使该芯片能够达到当今大规模 AI 工作负载所需的广泛规模。
他们写道:“DMA引擎采用多通道、高带宽传输架构,支持1D/2D/3D步进式移动,使得常见的机器学习张量布局能够在片上SRAM、HBM和外部接口之间高效移动,同时实现数据移动与计算的重叠。此外,片上网络(NoC)提供跨集群和内存子系统的可扩展、低延迟通信,并支持单播和多播传输——这对于分发张量块和协调并行执行至关重要。”
微软推出其首款专为人工智能推理而设计的AI加速器Maia 100至今已超过两年。Maia 100采用台积电5纳米工艺制造,提供1.8 TB/s的双向内存带宽和64 GB的SRAM。其MXFP4性能为3.2 petaflops,FP8或MXInt8性能为1.6 petaflops,约为Maia 200的三分之一。
微软云和人工智能执行副总裁斯科特·格思里表示,Maia 200 的功能与其他顶级 AI 加速器非常匹配,使其成为“AI 推理的强大引擎”。他在今天的一篇博客文章中写道: “实际上,Maia 200 可以轻松运行当今最大的模型,并且未来还有很大的空间运行更大的模型。”
Guthrie继续说道:“Maia 200是所有超大规模数据中心运营商中性能最强的第一方芯片,其FP4性能是第三代亚马逊Trainium的三倍,FP8性能也优于谷歌第七代TPU。此外,Maia 200也是微软迄今为止部署的最高效的推理系统,其每美元的性能比我们目前部署的最新一代硬件高出30%。”
Maia200 可在风冷和水冷环境下运行。它专为与 Azure 的第三方 GPU 集群配合使用而设计,并遵循机架、电源和机械架构标准。它已集成到 Azure 的原生控制平面中,微软表示这使得部署和维护变得轻而易举,同时还能与其他 AI 加速器在同一数据中心环境中和谐共存。
微软计划利用其 Maia 200 芯片运行多种模型,包括最新的 OpenAI GPT-5.2 模型。此外,该芯片还将用于生成合成数据,供人工智能模型进行训练。
参考链接
https://blogs.microsoft.com/blog/2026/01/26/maia-200-the-ai-accelerator-built-for-inference/
(来源:编译自microsoft)
*免责声明:本文由作者原创。文章内容系作者个人观点,半导体行业观察转载仅为了传达一种不同的观点,不代表半导体行业观察对该观点赞同或支持,如果有任何异议,欢迎联系半导体行业观察。
转自头条号《半导体行业观察》
文是楼上发的,图是楼上帖的,寻仇请认准对象。
有些是原创,有些图文皆转载,如有侵权,请联系告知,必删。
如果不爽,请怼作者,吐槽君和你们是一伙的!请勿伤及无辜...
本站所有原创帖均可复制、搬运,开网站就是为了大家一起乐乐,不在乎版权。
对了,本站小水管,垃圾服务器,请不要采集,吐槽君纯属用爱发电,经不起折腾。

















暂无评论内容